- Nasira – A FreeNAS build
- Nasira – Part II
- Nasira – Part III
- Nasira with a little SAS
- Moving Nasira to a different chassis
- When a drive dies
- Adding an SLOG… or not
- Coming full circle
- Throwing a short pass
- More upgrades but… no more NVMe
- Check your mainboard battery
Let me preface this: for most home NAS users, any kind of cache devices with ZFS are a waste. Only if you are frequently copying a lot of files to your NAS or modifying those files in place will an SLOG help. And a read cache device (L2ARC) has very few use cases where they are beneficial, almost none of which apply to home NAS.
And this is especially true if you don’t have a faster than Gigabit connection to the NAS. Without that, an SLOG or L2ARC is all cost and no benefit.
I’m a photographer, meaning I’m backing up several tens of gigabytes of initial RAW files from my camera to later be culled and edited. I also have a lot of movies backed up onto my NAS and recently started doing the same with my PS3 and PS2 games. So that’s a lot of medium and large writes going outbound. I also have a 10GbE network connection to the NAS.
Recently I also discovered that NFS is available on Windows 10 Pro, which I have on my desktop system. So I decided to enable that and remount my file shares using NFS since it’s supposed to be better than SMB in terms of performance.
And it…. wasn’t. Far from, actually.
But NFS is faster than SMB! That’s what everyone says at least.
Well, yes, overall it is. There are plenty of metrics that prove such. But why is it slow on Nasira?
It involves a third acronym: ZIL. The ZFS Intent Log. How it works and the kind of performance you’ll get will depend on the “sync” setting for the pool. Here’s the long and short of it:
- “disabled” = all writes are treated as asynchronous
- “standard” = only writes declared as “synchronous” are treated as such, asynchronous otherwise
- “always” = all writes are treated as synchronous
“Disabled” is fastest but least safe, and “always” is slowest but most safe. And “standard” is going to vary between the two depending on what you’re copying and what’s doing the copy.
Let’s get a little technical. ZFS writes data to your pool in “transaction groups”. If you’re familiar with relational databases, it’s a similar concept. With synchronous writes, the intent log is a mirror copy of the transaction groups stored in memory. If something goes wrong, having that mirror copy allows some level of data recovery. This is definitely a good thing.
And unless you have a separate log device, the ZIL sits in the pool itself.
On the platter HDDs.
And based on my testing and that of others, the NFS Client in Windows always operates synchronously. Meaning write speeds were… not even close to fast enough to saturate a GbE connection, let alone a 10GbE connection. Set “sync” to “disabled” and write speeds to the NAS were coming in around 300 to 400 MB/s. It was also a sustained speed as well, holding about steady around that mark. Whereas SMB file transfers would peak early then drop down to around 200 MB/s unless I used robocopy to force more data down SMB’s throat.
So the solution, then, is simple, right? Just add an SLOG device?
Latent issues
Now if you’ve been researching whether to integrate an SLOG device to your NAS, you’ve probably come across the term “latency”. A lot. And you’ve probably even come across a lot of web and Reddit posts that boil down to, in short, if you’re not using an Optane, you might as well not have an SLOG.
Yeah there’s a lot of religious undertones with TrueNAS and ZFS. I mentioned it in my first article discussing Nasira with regard to ECC RAM, and you can say the same about using an SLOG.
So what gives?
Well it’s namely because Intel’s Optane devices are some of the best in terms of latency and throughput. But how much does latency matter? It’s important, don’t get me wrong. But not to nearly the degree so many people think. And this all or nothing thinking does nothing to further the conversation.
Now obviously there are options you absolutely should not be using as an SLOG. Any SSD that is actually slower than your pool in overall write throughput (check by turning sync to “Disabled”) is a setup you definitely should not touch. This means that in any decent NAS setup, most any SATA SSD on the market is breaking even unless you’re striping two or more together, while most any NVMe SSD is going to be adequate. Just pay attention to write throughput.
And why do I say that? Why am I not joining in on saying “Optane or don’t bother”?
Because the metric that matters isn’t latency and throughput, but latency and throughput compared to your pool. It doesn’t matter if the drive you select has the best metrics available, but whether it’s better than your pool.
Since the idea is to give ZFS a location better than your pool for writing the intent log.
And the latency and write throughput of most any NVMe SSD on the market should easily outpace a pool of HDDs.
And if you’re lucky enough to have terabytes of SSD storage in your pool, why are you even thinking of adding an SLOG? Well, there is one benefit to it that I’ll touch on later. You’ll probably have to stripe NVMe SSDs together, though.
What about all that other stuff?
Oh you mean things like power loss protection and mirroring the SLOGs? None of that matters nearly as much as the zealots like to believe.
Again, a lot of talk about ZFS and “best practices” has taken on religious and apocalyptic undertones with talks about specific risks being thrown out the window with an all-or-nothing “no risk is acceptable” type point of view – hence the “ECC or don’t bother” type thinking I saw when first building Nasira. But then I shouldn’t be horribly surprised by the risk aversion of the average person (let alone our governments) given how things played out during the COVID-19 pandemic, and still are even today (as of when I write this).
Yes, I went there.
And it’s this near-complete “no risk is acceptable” type of risk aversion that seems to have flooded discussions on whether you need to mirror your SLOG and whether you need power loss protection. So let’s inject some sanity back into this, starting with mirroring the SLOG.
“Mirror, mirror of the SLOG”
How could data loss occur without a mirrored SLOG? Well two things have to happen pretty much simultaneously: your NAS crashes or loses power before the in-flight transaction groups are written to the pool, and the SLOG device dies either at the same time or it dies on reboot.
Since having a copy of the synchronous transaction groups in case the system does crash or lose power is the purpose of that intent log. Asynchronous transaction groups are lost regardless.
So if the SLOG gives up the ghost, meaning in-flight transactions cannot be recovered, you’ve got some corrupted or lost data, depending on what was in-flight. Provided there were in-flight synchronous transactions when that happened. Having a mirrored SLOG should protect you from that to a degree. And there’s always the chance the mirror completely gives up the ghost.
Here’s the million-dollar question, though: how likely is that to actually happen?
In actuality, it’s so low a likelihood I’m surprised people actually give it any thought. And there are steps you can take when building and deploying your NAS to keep the risk of that as low as possible. And it goes back to what I said when I built Nasira: use quality parts!
And primary storage devices normally don’t just up and die without any kind of warning from your system, especially if they’ve been in service for a significant period of time. So make sure you have S.M.A.R.T. monitoring turned ON and that you’re not ignoring the alerts your system is generating.
How bad of a time you’re going to have should that happen depends entirely on your use case. If a backup was in progress, then it’s not a huge deal. Just redo the backup when everything is back online. If you’ve just ripped a 4K UHD disk and was in the middle of copying the file to the NAS when everything went down, redo the copy when everything is back online. If you were ripping the disk to the NAS, just delete the partial output file and redo it.
If you’re editing photos or video straight from your NAS, then you’re in a bit more of a bind.
If your SLOG dies while the system is still live, though, ZFS will revert to putting the intent log back onto the pool and detach the log device. You may notice some performance degradation on writes, depending on your workflow, but the system will otherwise keep chugging away and you’ll get a notification that you need to replace the device.
So what about power loss protection, then?
Keep the power on!
Power loss protection is supposed to keep the SSD powered on just long enough to flush its internal cache should the system power off unexpectedly. Typically this is in the form of capacitors or an external battery. And the controller or adapter may have this as well in case the drive does not.
But do you really need that? Likely not. No, seriously, you very likely don’t need that. Since there are ways to protect your system from just losing power.
For starters, have an uninterruptible power supply (UPS) externally, and use a quality power supply internally with quality power cables. Again, use quality parts!
And like storage devices, power supplies generally don’t die without any kind of warning. And that warning comes in the form of system instability. So ignore that at your own peril! And that system instability could signal a problem with the power cables or the power supply itself.
If you really want to go all-out, use redundant power supplies. But I’ll leave you to determine if that’s worth the cost to you and your use case. For most people, the answer will generally be a No. You’ll likely know if your answer is a hard YES.
But whether you need power loss protection on your SLOG drives comes down to your use case. If you’re not working directly with the files on the pool, such as, again, editing photos and videos straight from it rather than using a scratch disk on your workstation, then not having power loss protection on the SLOG is likely not a big deal.
It all comes down to how much risk you’re willing to accept. Since losing the SLOG only risks losing in-flight synchronous writes. But then, if you’re talking about a mission-critical system where losing in-flight synchronous writes means a really bad time, I really hope you’re not using a DIY storage solution.
Never interrupt a writer!
And there’s one other detail as well: interrupted writes/saves = corrupted data.
And mirrored SLOGs and power loss protection cannot protect against that.
Interrupt the rip of a BluRay or 4K UHD disc to… anywhere, for example, and the output file is basically useless. And interrupting writes to a file would produce the same result for most file types. Interrupt the writes to database files stored on your pool and you might as well just restore from a backup.
Adding the overkill drive
So… what did I select?
To ensure I had write speeds in excess of what 10GbE could give, while not spending a substantial amount of money (e.g. Samsung, WD Black, etc.), I went with the HP EX900 Pro. 256GB. Absolute overkill on space. But rated at up to 1,900 MBps on sequential writes. More than enough to handle a fully-saturated 10GbE link.
Now the process to actually add the drive is beyond the scope of this article. I’m taking this as a chance to merely mention the upgrade and how I selected the drive, some pointers to keep in mind. And one place where you need to pay attention is PCI-E link speeds. For Nasira’s mainboard, it’s this chart in the manual:
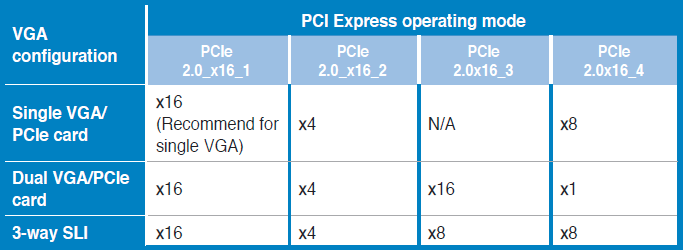
Initially when I added the SSD with its adapter card to the system, write speeds were… not what I expected. At first I thought I did something wrong adding the SSD. Well initially I added it as a cache device, not a log device. But once I corrected that, write speeds were again far below what I hoped.
So what was the issue? PCI-Express lanes. I first added the card to the system in the 2.0x16_4 slot thinking the operating mode that would apply is the first line. The SAS card is in 2.0x16_1 and the 10GbE card is in 2.0x16_2. So then I looked at the PCI configuration to see how many lanes the drive was getting.
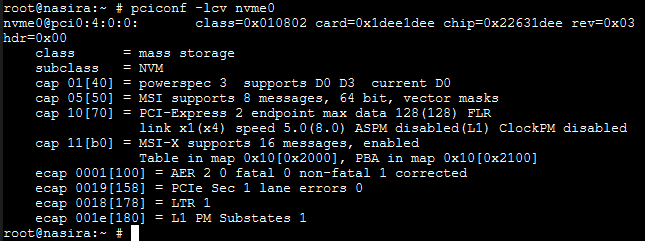
Just 1 lane. If this was a PCI-E 3.0 mainboard, that wouldn’t be a huge deal. Not ideal, but not crippling. Being a 2.0 mainboard, though, it needs all the lanes it can get.
So I moved the drive to the 2.0x16_3 slot. This meant having 3 cards crowded together, so not ideal. Did that improve write performance? Over NFS compared to no SLOG, it did. Like order of magnitude improvement.
Pool topography matters
In all the articles describing how SLOG devices improve write performance to the pool, they all omit one. key. detail. The pool topography. And along with topography is how fragmented or balanced, or not, your pool is.
And Nasira is arguably a worst-case scenario on all of that. Six (6) vdevs, all mirrored pairs, no common size (4TB to 12TB), with each pair added at different times as space filled up on the pool. This means heavy imbalance or fragmentation, with no way to alleviate except dump the pool to the cloud, wipe it, and pull everything back down. A process that would take… probably 2 weeks both ways. Even copying off to a pair of high-capacity HDDs would not change that.
After accounting for network throughput, write performance to your pool is throttled first by the intent log, then second by the actual writes to the pool. Without an SLOG, you’re doing writes to the pool twice. With the SLOG, you’re writing first to that device, then to the pool. This improves performance… to a degree. It’ll never be faster than full asynchronous writes, and that metric can give you an overall idea of how well your pool is performing.
And, again, pool fragmentation matters. ZFS will write data out according to the free space available per vdev. The more imbalanced your pool, the slower your writes (and reads) will be regardless of whether you have an SLOG or not.
But one benefit no one seems to mention about having the SLOG: it reduces the overall I/O going to your vdevs, helping their lifespan. So even if you don’t get a substantial performance increase adding an SLOG, you at least get that benefit. This could matter more with SSD-based storage, which will grow in popularity as prices continue to come down.
Conclusions and TL;DR
Let’s summarize.
First, it’s not entirely correct to say that any SSD as an SLOG is better than none. You need an SSD that will be faster than the write speed to your pool, or you’re not doing yourself any favors. Since, again, the idea is to give ZFS a better spot than your pool for writing the intent log.
For most everyone, this means most any NVMe on the market should suffice. Just make sure to go with a quality brand and read reviews to make sure you’re getting one with decent throughput.
Do you need power loss protection? Likely not.
If your NAS is light duty, you’re not writing to it much and only really using it for backups, power loss protection is extra cost for no extra benefit. Just make sure you have a quality power supply and watch out for symptoms it may be failing. And have a quality UPS as well that outputs pure sine wave power to keep your power supply running well for years.
Do you need to mirror your SLOG? Likely not.
Like with power loss protection, mirroring your SLOG is extra cost for no added benefit if your NAS is light duty. The risk of actual data loss should your SLOG device die is minimal because the risk your SLOG will die without any kind of advance warning is also minimal.
And the possibility it’ll die at the same time your NAS crashes or loses power while you have synchronous writes in-flight is so low you really shouldn’t be giving it much thought. Just make sure you have S.M.A.R.T. enabled and pay attention to any warnings the service sends out. And if it dies while your system is still live, you lose performance, but all your data should still otherwise survive.
So, again, if you want to add an SLOG device, just pick a quality NVMe SSD, buy an adapter board if you need it to put it in a PCI-E slot, and call it a day.
You must be logged in to post a comment.