Before diving in, let’s first establish my use case, which is likely very similar to yours.
I have Docker deployed to my virtualization server with plenty of containers running on it – Portainer, Frigate NVR, Bitwarden, etc. – plus a couple VMs. And I started using Traefik after discovering it with my current employer’s Kubernetes clusters.
For the uninitiated, Traefik Proxy, specifically, allows you to use hostnames to route traffic to your containers rather than relying on port numbers. Then you just need to make sure you have proper DNS resolution for the new hostname. Traefik then uses routing rules to determine which container gets the traffic, keying off the hostname provided via SNI or the Host header in an HTTP request.
And it’s a far less complicated means of putting your browser-accessible containers and services behind an HTTPS proxy.
Almost all of the containers deployed to my Docker server are isolated to their own networks and spun up or down using docker compose. Only two of those Docker services are not behind Traefik: Plex and a MySQL container I use for GnuCash. The MySQL client supports SNI as of version 8.1.0. GnuCash relies on DBD::MySQL, which does not support SNI as of this writing. Plex requires host networking when deployed as a Docker container.
And so does Traefik if you want it to route traffic seamlessly.
Traefik also makes a binary distribution you can run as a service outside Docker. And it might be available from your distro’s package manager. But beware that it may not be the latest version, so you might be missing out on critical security updates like the CVE fix in v3.6.7, the latest version as of this writing.
It’s safe to say, though, that the vast majority of Traefik deployments are via docker compose or the Helm chart for Kubernetes clusters. And as mentioned, I have Traefik deployed via Docker, which is where this comes in:
services:
traefik:
image: traefik:v3.6
container_name: traefik
restart: unless-stopped
network_mode: host
volumes:
- type: bind
source: /var/run/docker.sock
target: /var/run/docker.sock
read_only: true
- type: bind
source: ./certs
target: /certs
read_only: true
- type: bind
source: ./dynamic
target: /dynamic
read_only: true
- type: bind
source: ./traefik.yml
target: /etc/traefik/traefik.yml
labels:
- traefik.enable=true
- traefik.docker.network=traefik
# When using host networking, you can't use the "api@internal" service.
# to access the dashboard. Instead you need to You have to link the
# dashboard (port 8080) to a new one.
- traefik.http.services.traefik.loadbalancer.server.port=8080
- traefik.http.routers.traefik.service=traefik
- traefik.http.routers.traefik.entrypoints=websecure
- traefik.http.routers.traefik.rule=Host(`traefik`) || Host(`traefik.localdomain`)
And alongside the docker-compose.yaml is this traefik.yaml for configuration.
global:
checkNewVersion: true
sendAnonymousUsage: false
log:
level: INFO
accessLog: true
entryPoints:
web:
address: ":80"
http:
redirections:
entryPoint:
to: websecure
scheme: https
permanent: true
websecure:
address: ":443"
http:
tls: true
# Add any other ports you need - e.g., 3306 for MySQL, 6379 for Redis, etc.
providers:
docker:
exposedbydefault: false
file:
filename: /dynamic/tls.yaml
api:
dashboard: true
insecure: true
And this is the folder structure where these files live:
So the above should be enough to get you started using Traefik with Docker. Change settings where you need – e.g., dumping logs to files instead of the output available via docker logs.
You will need to read the documentation for deploying your individual services with the proper labels so they are properly picked up by Traefik.
You’ve probably seen variants of this floating around:
On February 4, 2026, the Supreme Court issued an order in Tangipa v. Newsom, Docket No. 25A839, that says simply:
The application for writ of injunction pending appeal presented to Justice Kagan and by her referred to the Court is denied.
A writ of injunction is a request by the appellant to a higher Court to order a lower Court to issue an injunction in a pending case. And the petition for that injunction was denied.
The case itself hasn’t been dismissed, nor is this any kind of final order or disposition. The case is still pending in the lower Courts. The only thing the appellants sought was an order to postpone use of the new maps still after the case is disposed, provided it’s disposed in California’s favor. And the Supreme Court denied that request. And since the appellants have no other recourse, they can’t seek any kind of injunction against use of the new maps unless something new enters the picture, like new maps.
Thankfully there are some media outlets who are properly reporting the current state of the case over acting like the case is now done. In an article for UPI, Mike Heuer says this:
Although the writ of injunction was denied, the ruling does not end legal challenges to the new map for California congressional districts that was approved by 64% of California voters on Nov. 4.
It does, however, increase the likelihood that the newly drawn districts will stay active during the Nov. 3 midterm election.
This is the correct interpretation of the Court’s action on Wednesday. Again the case is still pending, and will likely still be fully pending beyond November.
Before Candace Owens became known as a conservative firebrand and commentator, she was a leftist. And as a leftist, she started a very small online publication called Degree180. And under that brand started a Kickstarter campaign for an online platform called Social Autopsy.
The project was panned from all sides. Owens and her company became public enemy #1 overnight.
So what was Social Autopsy? It was a platform for doxing and deanonymizing people en masse. The devastation such a platform would have wrought on the world, had it actually gotten off the ground, cannot be understated. I’ll let her own FAQ video shed light on this:
Surprisingly that video is still live – at least as of the time this article went public. It was released March 22, 2016. Keep that date in mind.
The Kickstarter went live on April 12, 2016, and… didn’t last long. In launching the campaign, Owens and her company did the smart thing and tried to create something… But if a later post by Owens was any indication, the site wasn’t supposed to be publicly available. But whoever was coding the site didn’t bother setting up even simple HTTP authentication to prevent that from happening. What little was there was collected by The Wayback Machine.
Part of the backlash against her came from both an expected and unexpected direction: Zoe Quinn. If you know anything about Gamergate, you know that name very well.
For the uninitiated, I’ll try to be brief.
Back in 2014, one of Zoe Quinn’s ex’s published a scathing article about her that became known colloquially as the “Five Guys” controversy as that is how many men the ex alleged Zoe Quinn had… engaged at various times. One such person was Nathan Grayson, a gaming journalist. At the time, Quinn had created a game called “Depression Quest” (still available on Steam) and was trying to get attention on it, so her affair with a gaming journalist became a focal point, even though her game hadn’t yet been completed at the time of the affair.
Prior to that article being published, massive collusion between game developers and media publications had long been alleged.
And what happened on August 28, 2014, certainly didn’t help any claims to the contrary.
Twelve (12) gaming publications published the same article, known as the “Gamers are Dead” article, on the same day. That is seen as the colloquial start of what became known as “Gamergate”. Actor Adam Baldwin – i.e., Jayne from Firefly – is credited as coining the term and starting the hashtag on Twitter.
One discovery that solidified just how right Gamergate was about the gaming media was the GameJourosPros mailing list.
The gaming media moved swiftly to control the narrative – and mostly succeeded, given the Wikipedia article on the topic – and reframed “Gamergate” as a hate campaign against women in gaming, eventually women in general, and, specifically, Zoe Quinn. Trying to dodge the allegations coming from Gamergate by acting like they were now trying to protect women and minorities in gaming or acting on their behalf, which led to the start of the NotYourShield hashtag.
Now the one thing that needs to be highlighted is how compressed the timeline for this actually was. The time between “Five Guys” article and the “Gamers are Dead” articles going live was… less than three (3) weeks. The long-standing allegations against the gaming media and developers, along with Quinn going after another group called The Fine Young Capitalists, a women-centric gaming development organization, led to this blowing up quick and violent.
YouTuber ShortFatOtaku (a.k.a., “Dev”) has a very good overview of the entire controversy:
And a pretty good timeline of the whole thing is available on Tiki-Toki. Yeah, there’s a LOT more to this than those trying to control the narrative want you to know.
I’d be lying if I said there was no harassment toward Zoe Quinn or any of the other prominent women in gaming – e.g., Anita Sarkeesian. But contrary to a very popular belief – again, just look at the Wikipedia article on it – the vast majority of the attention of Gamergate was directed at the gaming media. Calling for greater transparency and an end to the massive conflicts of interest that were uncovered. Zoe Quinn was a tiny blip on Gamergate’s radar and practically non-existent on their list of targets.
But she used her victimhood from that to form a non-profit called “Crash Override Network” aimed at providing resources for those experiencing online bullying.
Anyway…
So what does Gamergate have to do with this? Because Quinn reached out to Owens while the Kickstarter was still live, and Quinn alleged that “Gamergate” would go after Owens. And it’s Candace’s response to Quinn that reveals that Candace Owens has… always been a conspiracy theorist.
Quinn’s one-off allegation did end up being true, but also incomplete. No one wanted Social Autopsy – except those hoping to use it for nefarious purposes. Everyone could see what Social Autopsy could turn into.
Everyone except… Candace Owens.
And she puts her penchant for conspiracy theorist thinking on display, along with her abject ignorance of the online space, in crafting one hell of a narrative, both in that post and on Twitter, in which Zoe Quinn and Randi Lee Harper turned to and led the Gamergate calvary to get Social Autopsy shut down.
Yeah, it’s… bizarre in the kindest terms.
So after all of that, Owens went dark online. Her above-linked response to Quinn & Co. was taken down sometime between September 14 and 17, 2016.
Her last post to Degree180 was on November 13, 2016. An article called “Dear Liberals… Love, Former Liberals,” which kind of hints at her… transition. Degree180 itself went offline sometime in 2017 when their hosting expired and wasn’t renewed. SocialAutopsy.com eventually went down as well, also sometime in 2017 when their hosting expired.
Sadly, though, the idea of a doxing site like Social Autopsy didn’t die with Social Autopsy as we saw with the high-profile leaks from the very insecure servers for an online platform called Tea. And contrary to labels, it wasn’t a hack. They just had the critical servers publicly exposed with no authentication, meaning anyone who could find the endpoints had access. And finding that information was pretty simple to anyone familiar with “developer mode” in a desktop browser.
Moving on…
July 9, 2017. Owens reappeared with a new YouTube channel called “Red Pill Black” and a new video called “Mom, Dad…I’m a conservative”:
Now was her… transition into a conservative genuine? Given the aforementioned article, I think so. Since it’s either that or she’s playing one hell of a long con. And she did say “Social Autopsy is why I’m a conservative.” So the conspiracy theory she manufactured to explain the backlash against Social Autopsy led her to becoming a conservative… Anyone seeing red flags on that?
Despite attempts to get her to do such, such as by Blaire White in an open debate on The Rubin Report on November 7, 2017, Owens has, as far as I’m aware, never openly and unambiguously denounced or disavowed Social Autopsy – and I welcome correction if someone has it. I mean, at least there’s video of Trump unequivocally denouncing white supremacists despite repeated claims he never did so.
So taking the above, it should be no surprise that Candace Owens has a history of running with wild theories. It’s one of the reasons Brigitte Macron, the First Lady of France, has filed suit against Owens for the outlandish theory that Macron is… Male-to-Female Trans. The lawsuit was filed in Delaware and is docketed as Case No. N25C-07-194.
And then there are all the wild accusations Owens has been throwing around regarding Charlie Kirk’s assassination on the scale of the kind of theories that the JFK assassination couldn’t possibly have been just a one-man operation. Now there is evidence suggesting that the person who carried out Kirk’s assassination had conspired or colluded with others before the fact but otherwise acted alone in carrying it out.
But Owens, for some reason, doesn’t seem to think the reality behind it is that simple. That the assassination plot extends well beyond the person who carried it out and a few other individuals close to the assassin. And Social Autopsy and the conspiracy theory Owens manufactured to explain the backlash to it shows that her penchant for conspiracy theorist thinking isn’t new or unordinary.
The bigger problem is how far her conspiracy thinking is now going.
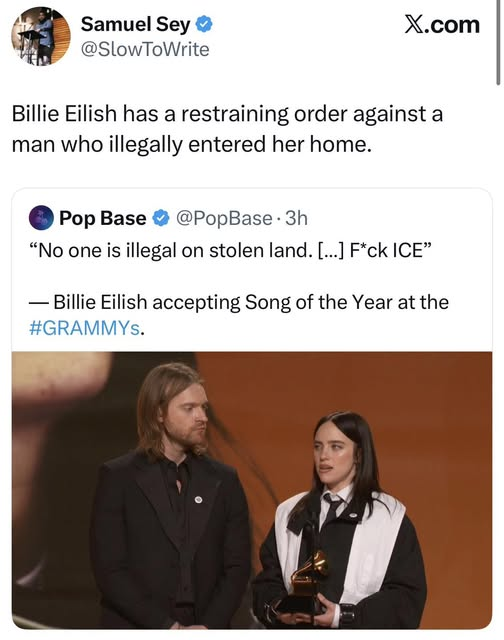
Let’s put this notion to bed already: “No one is illegal on stolen land”. A statement that sounds enlightening to the unenlightened, intelligent to the unintelligent.
Sovereignty is the name of the game here. You either have it or you don’t. There is no in-between.
Libertarians argue that everyone has their own personal sovereignty. And that we cede some of that sovereignty to create governments to protect that personal sovereignty. In much the way States ceded some of their sovereignty when creating the Federal government via the Constitution.
Part of the personal sovereignty we ceded to create governments is the power to make and enforce laws. So let’s take this to its logical conclusion.
“Stolen land” means there is an illegitimate claim to it. And I’ll avoid diving into the complication that would create if you tried to unravel that. Since… if you were to actually try to completely unravel that, you’d be talking about undoing millennia of land conquest across the world. Including by the various Native American Tribes in North and South America. Yeah, no, they absolutely are NOT innocent in history, and it’s about fucking time leftists stop pretending they are.
But, again, to say that the land occupied by the States comprising the United States is “stolen land”, you are, in short, saying that the sovereignty of the United States and all States therein is illegitimate. And by saying that, you are, by extension, saying that the Constitution is illegitimate because the sovereignty of the States that created it is illegitimate.
And the sovereignty of the States is illegitimate because the sovereignty of the people who created those State Constitutions is also illegitimate.
Again, there is no in-between.
This all means the United States has no right to national defense, since national sovereignty implies that right. So if any other country were to come into the United States and try to take us over, our military should, in short, just stand down and… let it happen. And, alongside that, anyone who wants to enter the United States is free to do so at any time and cannot be removed for any reason – i.e., “no one is illegal on stolen land”. No one can have an immigration status, so no one can have an illegal immigration status because… the sovereignty of the United States is illegitimate.
And before you scream “actually… your argument is invalid because it’s a slippery slope”, a slippery slope argument is not prima facie invalid, though a lot of people like to argue such. Because they can’t respond to what’s been said, and so need an easy out while screaming “Your argument is invalid, so I win by default!” Yeah… no.
Especially since we are seeing that very slippery slope play out in real life. With the attempts to interfere with immigration enforcement that have already led to two high-profile deaths.
And we’re seeing the erosion of sovereignty – both Federal and State sovereignty – play out in leftist cities when it comes to property rights – i.e. personal sovereignty – and the abject refusal by city and State prosecutors to actually prosecute personal property crimes like theft and squatting, which has led to some interesting political swings as well.
Yet Billie Eilish wants her property rights protected, hence the restraining order.
Again, you can’t have it both ways. Either the sovereignty of the United States is legitimate, meaning so are any laws passed that comply with the Constitution, or it is not.
Saying “no one is illegal on stolen land” immediately implies you see the sovereignty of the United States as illegitimate. So… when are you leaving?
Contrary to popular belief, affidavits aren’t infallible.
People lie in affidavits… all. the. time. People lie on the stand under oath… all. the. time.
And that’s simply because… there’s largely no penalty for doing so.
You see… perjury is a rather… interesting crime. I wrote an article 10 years ago about the difference between “I don’t believe you” and “You’re lying”. And it boils down to whether I can prove that 1. what you’ve just said to me is false and 2. that you knew at the time you made your statements that they are false. Welcome to Perjury 101 and why I said there is largely no penalty for lying under oath, whether on the stand or in an affidavit.
The simple reality is that… perjury prosecutions are very, very few and far between. Even when there is a “smoking gun”, a perjury charge that could be easily proven beyond reasonable doubt – e.g., Bill Clinton lying under oath about his affair with Monica Lewinsky – there still may not be a prosecution for it.
The fact there’s largely no consequence to lying under oath – aside from losing out on whatever the lying was trying to facilitate or protect – means that you should always treat an affidavit or someone’s testimony with skepticism. Lots and lots of skepticism.
Someone attesting to something in an affidavit doesn’t make those statements prima facie true.
Since… anyone can really attest to anything “under penalty of perjury”. Such is about as meaningful as swearing to something with your hand on the Bible. Neither make lying impossible, yet many are quick to presume such.
Affidavits are often given the presumption of being incorruptible, infallible, and they’re treated as if they’re immune to being incorrect and, therefore, unimpeachable. Such as the above screenshot from an affidavit from the latest Epstein file drop.
Why would would someone attest to something in an affidavit that isn’t true, right? That’s about like asking “why would someone lie?” Not just “lie under oath”, but “lie” in general.
And one reason is, again, that the risk of actually being prosecuted for perjury is extremely low. Not zero, sure. But those prosecutions definitely aren’t happening as often as they really should be. Witnesses provably lie on the stand all. the. time. Yet almost none of them are prosecuted for it. Attestants to an affidavit provably lie in affidavits all. the. time. And yet… almost none of them are prosecuted for it.
And that is due to how due process actually works in criminal cases. The burden is entirely on the prosecutor to prove beyond reasonable doubt that 1. the statements in the affidavit are false and 2. the attestant knew at the time they attested to it that it is false. There are so many things that work against this, making perjury a damned hard charge to prove.
And if the statements in the affidavit are not provable either direction – meaning there is no evidence supporting the statements and nothing to prove they are impossible – then you can’t prove perjury occurred since you can’t prove the statements are false. Absence of evidence is not evidence of absence. And an example of this is the attestant to an affidavit or a witness under oath testifying to something that happened several decades ago for which no evidence is possible supporting the statements.
An easy example of that is Christine Blasey Ford, PhD, and her testimony against the confirmation of now-Supreme Court Justice Brett Kavanaugh. Pretty much everything Ford testified to was not provable. But because she was making those statements under oath, many presumed them to be correct merely on her assertion they are correct.
And people do much the same with affidavits, presume the statements are true or must be true even when they aren’t provable simply because someone was willing to sign their name to a piece of paper.
But when there is no penalty for lying, why should affidavits or testimony be trusted at all?
Again, in a perjury prosecution, the prosecutors have the burden of proving the statements false. Sometimes that’s easy – e.g., Bill Clinton and Mark Fuhrman. But rarely is that the case unless you have a “smoking gun”.
But even having a “smoking gun” doesn’t guarantee someone will be prosecuted for perjury.
Never accept an affidavit at face value. And if the affidavit is making claims that are not provable in either direction, there is no reason to accept it as true unless there is other corroborating evidence. But generally affidavits are gathered because there is no other corroborating evidence.
David Wise, 59, originally borrowed $79,000 in student debt, has paid back $175,000 of it over four decades, but still has a balance over $200,000.https://t.co/s6ibFIunCl
— The Debt Collective 🟥 (@StrikeDebt) May 12, 2022
Let’s throw some numbers on this…
First, I doubt he borrowed the $79 thousand up front. Instead that was probably how much he borrowed across 4 years. So from, I presume, about 1982 to 1986. Which really was one of the worst times to be borrowing money due to inflation.
I’ll also presume the loan was in deferment while he was in school, so interest was being assessed that entire time unless he was making payments to at least keep up with that.
Now back in the 1980s, the total amount you could borrow through the Stafford loan program – i.e., “Federal student loans” – was $2500 per year according to this article. Stafford loans have the benefit of a capped interest rate. They’re still variable rate loans, but they were capped at 8%. In the 80s, this meant the interest rate was less than inflation. But capped interest rate also meant limited borrowing.
Again, it was limited to only $2,500 per year. Yet on average, Dave was borrowing nearly $20 thousand per year. So that extra $17,000 per year he borrowed would’ve come from private lenders and was not Federally insured. Meaning Dave was borrowing at whatever interest rate the banks came up with. And it was likely a variable interest rate as well.
And if the loan was in deferment while he was still in school, he likely accumulated interest across his 4 years in school such that he, in effect, owed about 1.5x what he borrowed in total. So already he was in the 6-figures for student loan debt and he hadn’t even started paying it back.
And that was in the 1980s. Just the principal alone, adjusted for inflation, would be about $230 thousand today. Add in the interest, which likely would’ve been capitalized – meaning, rolled into the principal – when he entered repayment, and that’s the equivalent of $300 thousand today.
And yet, he was paying on average… from late-1986 into 2022, so about 35-1/2 years… about $400 per month. On 6-figures of student loan debt.
And in that time, he’s accumulated $121,000 in interest at a rate of about $285/mo. Meaning the total interest being assessed averaged, given his monthly payment, probably about $675 per month, meaning an average interest rate of about 10%.
To get out from under the loans would’ve required him… probably tripling his monthly payments. Doubling would’ve at least overtaken the interest being assessed and allowed the principal to reduce. But tripling his payments was really the only option to make substantial headway and get the loans paid off in a more reasonable timeframe.
He should also have tried refinancing the loans at the various times when interest rates were at their lowest.
The Constitution limits the government in its dealings with anyone, whether they are a citizen or not, legal immigrant or not. The Fifth Amendment says clearly “No person…” Something Lippincott would know if he’d actually read it. The Due Process Clause requires an adversarial process wherein a person who is being held by the government can challenge that detention and the reasons for it. Meaning if a person is detained by ICE on suspicion of being an illegal alien, the person being detained must be given a chance to challenge that before some properly appointed tribunal or a Court of Law.
Article Three of the Constitution also says the judiciary has jurisdiction over “all Cases, in Law and Equity, arising under this Constitution, the Laws of the United States, and Treaties made, or which shall be made, under their Authority”. That includes enforcement of Title 8 of the United States Code, which is Federal immigration and naturalization law.
As 2025 was coming to a close, along with the Chiefs season as they finished out with a losing record, there was another Chiefs-related event that went unnoticed. I’m not finding anyone talking about this, at least. And a Google search brings up nothing. And I decided to go looking into the case after being reminded of it recently.
First, let’s rewind to the tail end of 2023. Deadspin published an article by Carron J. Phillips in which he singled out a 9 year-old Chiefs fan with some rather disgusting statements against him and his parents. In response, the family of the 9 year-old filed a lawsuit against Deadspin’s then-parent company, G/O Media, in Delaware, the State where G/O is incorporated.
Not long after the lawsuit was filed, Deadspin was sold off to Lineup Media and their entire staff laid off.
In 2024, G/O tried a bit of a last-ditch effort to quash the lawsuit. And in October 2024, they were slapped down, with the Court saying that the Deadspin article made “provably false assertions of fact”. After that ruling, I said this on a private Facebook post:
Deadspin’s new parent company just needs to settle this. The only thing continuing to fight this lawsuit will do is just cost them more. Talk with the family, come up with a number, create a college and trust fund for the kid, give a heavy donation to the Tribe the kid and his father’s family belongs to, and just end it…
The case is N24C-02-051 – Raul Armenta, Jr., v. G/O Media – filed in the Delaware Superior Court for Newcastle County. After the Court ruled against G/O, the case proceeded to discovery starting later in October 2024. And per typical with discovery in a civil case, motions flew back and forth into August 2025. Then… they kind of stopped.
The last motion in August 2025 was directed at G/O media to “compel G.O Media to produce financial documents, improperly withheld documents, and social media messages”. Opposition to that motion was filed a month later.
Then the docket went quiet.
November 13, 2025, a little over a year since the Court slapped down G/O media, another docket entry. A “confidential petition for approval”. So I guess that “motion to compel” told G/O they were… screwed, and they spent the next couple months negotiating behind the scenes on a settlement.
Which would be approved on December 16, with the case officially dismissed with prejudice on January 6, 2026, with the final order of dismissal filed on January 8.
So one of the most egregious defamation cases in modern journalistic practice was very recently settled out of Court on undisclosed terms. And it really should’ve ended at the end of 2024 and not been dragged out another year.
You’ve probably seen numerous times the marketing statement “9 out of 10 dentists recommend”. So… “not all dentists” make whatever recommendation follows that. And it’s perfectly reasonable to say “not all dentists recommend using…” specific dental hygiene product.
However if only 1 out of 10 dentists make a certain recommendation, saying “not all dentists recommend using…” is technically accurate but extremely misleading.
Whenever I hear “not all”, you’re basically telling me it’s a small minority, typically including the person uttering “not all”, who are excluded from whatever follows “not all”. A few more insidious examples.
“Not all men are rapists”. So an overwhelming majority are? Absolutely not.
“Not all blacks are criminals.” Only a minority of blacks commit crime.
“Not all gun owners commit crime.” Again, it’s only a minority of gun owners.
And, more starkly, “Not all gun owners commit mass shootings” is not the same as the far more accurate statement that “The vast, vast, overwhelming majority of gun owners do not shoot anyone”. (I’ve been a gun owner for 16 years and have never discharged my firearm except at a gun range.)
And on this topic is a phrase that I’ve seen come from women a lot: “It’s not all men, but always a man”. Which 1. dismisses the fact that women do commit sexual harassment and assault against men and other women – on which I have personal experience on the former – and 2. pulls the fallacy of making it sound like it’s only a minority of men who do NOT commit sexual harassment and sexual assault.
It’s like saying “It’s not all blacks, but always a black person” (or a black man) when talking about crime. Which makes it sound like the overwhelming majority of blacks, and only blacks, commit crime.
Venezuela needs change. Just like Iran, Russia, China, and plenty of other countries around the world. Including Ukraine. And if you don’t know why I’m including them, let me just say that Zalinsky isn’t as friendly as you’ve been led to believe. Remember, the enemy of your enemy is NOT your friend. Anyway…
Venezuela has demonstrably gone downhill since the Chavez government took over in 2002 and started trying to nationalize *everything*. Which that unto itself wouldn’t have been the nails in the coffin for Venezuela, except Chavez – and the later Maduro regime – replaced those who knew how to run the businesses with their political cronies. And when you replace someone who knows what they’re doing with a puppet of the State who ticks all the right political boxes… poverty is the inevitable result.
Just look at their nationalized oil industry. Chavez replaced all the people who knew how to run it with his cronies. And that’s one of the ways Venezuela went from one of the wealthiest countries in South America to one of the poorest in the world. And that’s why socialism inevitably fails… Because those in power favor political alliance over expertise…
So while Venezuela has demonstrably gone downhill and there are numerous human rights violations that likely warrant Maduro being taken to The Hague to stand trial, we should not have gone in and done this without international cooperation. If there was an arrest warrant against Maduro from the International Criminal Court, that’s one thing. But as far as I’m aware, there is no such warrant.
So… this is just about regime change. And the Trump administration installing a puppet government of its own… not a good look on our own domestic front, let alone the international stage.
The United States has tried regime change off and on since WWII. It’s never ended well. Since the fear now is… will Venezuela become another Afghanistan, Libya, or Iraq? And by that, I mean, will someone just as bad or worse than Maduro seize power and plunge Venezuela back into extreme poverty after we leave? History leans toward that being a Yes.



You must be logged in to post a comment.