- Nasira – A FreeNAS build
- Nasira – Part II
- Nasira – Part III
- Nasira with a little SAS
- Moving Nasira to a different chassis
- When a drive dies
- Adding an SLOG… or not
- Coming full circle
- Throwing a short pass
- More upgrades but… no more NVMe
- Check your mainboard battery
In the previous iteration, I mentioned my intent to add more NVMe drives to Nasira. Right now there is only one that is being used as an SLOG, which I’m debating on removing. But the desire to add more is so I can create a metadata vdev.
Unfortunately doing that with the Sabertooth 990FX mainboard currently in Nasira is going to be more trouble than it’s worth. So to find something easier to work with, I considered ordering in a Gigabyte GA-990FXA-UD5 through eBay. But I realized I had a GA-990FXA-UD3 lying around unused. So I did some research into whether that would suit my needs.
And it looks like it will.
What’s the issue?
First, let’s discuss what’s going on here.
With the AMD FX processors, the chipset controlled the PCI-E lanes, not the CPU. This was a significant difference between AMD and Intel at the time. Though the CPU now controls the PCI-E lanes and lane counts with Ryzen.
And the 990FX chipset has 42 PCI-E lanes. This surpasses the lane count available on any Intel desktop processor at the time. The Intel i7-5960X had 40 lanes. Only Intel’s Xeon surpassed it, and only if you used more than one of them.
How they were divvied up between slots was up to the motherboard manufacturers, but generally every 990FX board gave you two (2) x16 slots so you could use Crossfire or SLI. What you could run and at what speed it ran depended heavily on the mainboard, since the mainboard determined lane assignments to slots. I’ve previously discussed how the Sabertooth 990FX assigns PCI-E lanes, showing the counter-intuitive chart from the user manual, so now let’s look at the Gigabyte lineup.
Gigabyte released three 990FX board models (with several revisions thereto) as part of their “Ultra Durable” lineup: the GA-990FXA-UD3, -UD5, and -UD7. And each has different lane assignments. The -UD7 is easily the most flexible, guaranteeing four (4) full-length slots at x8 or better. The UD5 guaranteed three (3) slots at x8 or better.
The -UD3 is a little different. That board also has 6 PCI-E slots: 2 x16, 2 x4, and 2 x1. And unlike the -UD5 and -UD7, the -UD3 does not share lanes between any of the slots or onboard features. Each slot has its own dedicated lanes. What you see is what you get. Or, at least, that is what the specifications heavily imply.


Why does this matter?
Obviously lane counts matter when you’re talking about high-bandwidth devices. You shouldn’t just randomly insert cards into slots without paying attention to how many lanes it’ll receive.
While any PCI-E device can operate on as little as just one lane – something anyone familiar with crypto-mining can attest – you definitely want to give bandwidth-critical devices all the lanes they require. SAS cards. 10GbE NICs. NVMe SSDs. You know, the hardware in Nasira.
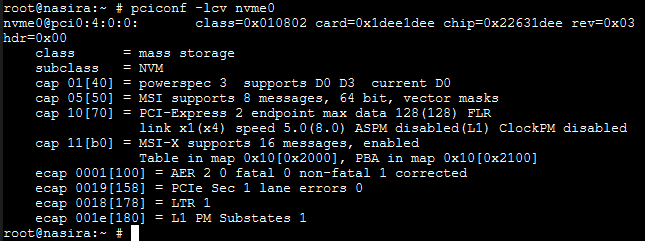
So when the NVMe SSD I installed as an SLOG reported up that it had only a x1 link, I needed to swap slots to get it running at a full x4. The Sabertooth 990FX divvies up its PCI-E lanes in a very counter-intuitive way, leading me to believe the NVMe drive would have its needed 4 lanes in the furthest-out slot where I wanted to run it. And it turned out that wasn’t the case.
Had I swapped out the board sooner for the -UD3 I have on hand (it wasn’t available when I initially built Nasira), I wouldn’t have run into that issue.
That this was all on a 990FX mainboard is immaterial. Indeed the issue is more acute on many Intel mainboards unless you’re running one of the Extreme-edition processors or a Xeon due to PCI-E lane count limitations.
And many mainboards have a mix of PCI-E versions, so you need to pay attention to that as well to avoid, for example, a PCI-E 3.0 card being choked off by PCI-E 2.0 speeds. This is why many older 10GbE NICs are PCI-E 2.0×8 cards. PCI-E 2.0×4 has just enough bandwidth for two (2) 10GbE ports, but 1.0×8 really has enough bandwidth for only one (1). While PCI-E 1.0×8 should, on paper, allow for dual 10GbE ports, in practice you won’t see that saturated on such PCI-E 1.0 mainboards.
And 3.0 x4 10GbE NICs, such as the Mellanox ConnectX-3 MCX311A, will run fine in a 2.0 x4 slot – such as the slots in my virtualization server and the X470 mainboard in Mira. And I think it’s only a matter of time before we see PCI-E 4.0×1 10GbE NICs, though they’ll more likely be PCI-E 4.0×2 or x4 cards to allow them to be used in 3.0 slots.
Thermals is the other consideration. You typically want breathing room around your cards for heat to dissipate and fans to work. SAS cards can run hot, so much so that I wanted to add a fan to the one in Nasira after realizing how to add one to the 10GbE NICs in my OPNsense router. And even for 10mm fans, I need at least one slot space available to give room for the fan and airflow.
So with all of that in mind, I swapped out the Sabertooth 990FX board for the ASUS X99-PRO/USB 3.1.
Wait, hang on a sec…
So after initially jettisoning the idea of a platform upgrade, why am I doing a platform upgrade? In short… memory prices right now. I was able to grab 64GB of DDR4-3200 RAM from Micro Center for about 200 USD (plus tax) – about 48 USD for each 2x8GB kit. Double the memory, plus quad-channel.
And PCI-E 3.0. That was the detail that pushed me to upgrade after looking at the PCI-E lane assignments with the 5820k, which is a 28-lane CPU. Fewer lanes compared to the 990FX, but still enough for the planned NVMe upgrade. (4 lanes to the 10GbE NIC, 8 to the SAS card, 16 to the NVMe carrier card.) While upgrading to the 5960X is an option to get more PCI-E lanes – they’re going for around 50USD on eBay as of when I write this – it isn’t something I anticipate needing unless I upgrade the SAS card.
It’s also kind of poetic that it’s my wife’s X99 mainboard and i7-5820k that will be the platform upgrade for Nasira. Since acquiring that board and processor freed up her Sabertooth 990FX and FX-8350 to build Nasira in the first place.
Performance
So how does the new platform perform compared to the old? Well this probably speaks for itself:
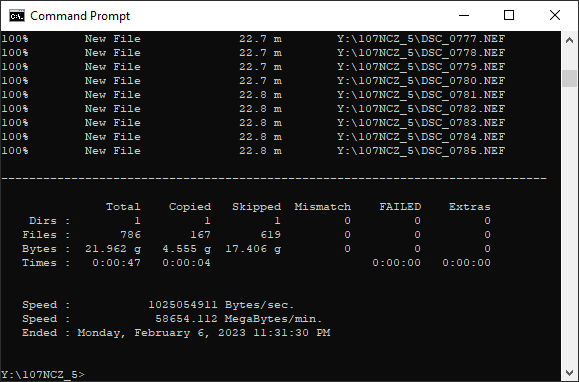
That is a multi-threaded robocopy of picture files from a WD SN750 1TB to one of the Samba shares on Nasira. That’s the first time I’ve ever seen near. full. 10GbE. saturation. That transfer rate is 1,025,054,911 bytes per second, which is about 997.6 megabytes per second. I never saw anything near that with the Sabertooth 990FX. Sure I got somewhat better performance after adding the SLOG, but it’s clear the platform was holding it back.
More and faster memory. Faster processor. PCI-E 3.0.
But… ECC….!!!
Hopefully by now the religious zealotry and doomsday catastrophizing around not using ECC with ZFS has died down. Or does it persist because everyone is copying and pasting the same posts from 2013? It seems a lot of people got a particular idea in their heads and just ran with it merely because it made them sound superior.
The move to the 5820k does mean moving to non-ECC RAM. And no, there isn’t nearly the risk to my pool that people think… I went with ECC initially merely because the price at the time wasn’t significantly more expensive than non-ECC, and the mainboard/processor combination I was using supported it.
And when I wrote the initial article introducing Nasira, I said to use ECC if you can. Here, though, I cannot. The X99 board in question doesn’t support ECC, and neither does the processor. And getting both plus the ECC DDR4 is not cheap. It’d require an X99 mainboard that supports it, plus a Xeon processor. Probably two Xeons depending on PCI-E lane counts and assignments. And as of when I write this, the memory alone would be over 50 USD per 8GB stick, whereas, again, the memory I acquired was under 50 USD per pair of 8GB sticks.
But, again, by now the risk of using non-ECC with ZFS has likely been demonstrated to have been well and truly overblown. Even Matt Ahrens, one of the initial devs behind the ZFS filesystem, said plainly there is nothing about ZFS that requires ECC RAM. So I’m not worried.
And if your response to this is along the lines of, “Don’t come crying when your pool is corrupted!”, kindly fuck off.
Because let’s be honest here for a moment, shall we? It’s been 7 years since I built Nasira. In that time, there have probably been thousands of others who’ve taken up a home NAS project using FreeNAS/TrueNAS and ZFS. With a lot of those likely also using non-ECC simply to avoid the expense needed to get a platform that supports ECC RAM along with the memory itself. A lot of them likely followed a similar story to how I first built out Nasira: platform upgrade that freed up a mainboad/processor, so decided to put it to use. Meaning desktop or gaming mainboard, desktop processor or APU, and non-ECC DDR3 or DDR4.
Now presuming a small percentage of those systems suffered pool corruption or failures, how many of those could be legitimately attributed to being purely because of non-ECC RAM with no other cause?
In all likelihood – and let’s, again, be completely honest here – it’s NEXT. TO. NONE. OF. THEM.
And with Nasira, if anything is going to cause data corruption, it’s likely to be the drive cables, power cables, or the 10+ year-old power supply frying something when it gives up the ghost. Which is why I’m looking to replace it later this year for the same reason as the other pair of 4TB hard drives: age.
Again, use quality parts. Use a UPS. Back up the critical stuff, preferably offsite.
Now that’s not to say there is no downside to not using ECC, as there is one: you’ll get quite a lot of checksum errors during scrubs. (Note: actually if you aren’t using ECC RAM and you do see checksum errors during scrubs or normal use, change out your mainboard battery.)
Current specs and upgrade path
So with the upgrade, here are the current specifications.
CPU: Intel i7-5820k with Noctua NH-D9DX i4 3U cooler
RAM: 64GB (8x8GB) G-Skill Ripjaws V DDR4-3200 (running at XMP)
Mainboard: ASUS X99-PRO/USB 3.1
Power: Corsair CX750M green label
Boot drive: ADATA ISSS314 32GB
SLOG: HP EX900 Pro 256GB
HBA: LSI 9201-16i with Noctua NF-A4x10 FLX attached
NIC: Mellanox ConnectX-3 MCX311A-XCAT with 10GBASE-SR module
The vdevs are six (6) mirrored pairs totaling about 54TB.
Soon I will be adding a metadata vdev, which will be two NVMe mirrored drives on, likely, a Sonnet Fusion M.2 4×4 carrier card. The SLOG will be moved to this card as well. That card doesn’t require PCI-E bifurcation, unlike other NVMe expansion cards like the ASUS Hyper M.2 x16 and similar cards, since it uses a PLX chip. But that’s why the Sonnet Fusion card is also more expensive. (X99 mainboards almost always require a modded BIOS to support bifurcation.)
There’s also the SuperMicro AOC-SHG3-4M2P carrier card. But that is x8, compared to x16 for the Sonnet Fusion. And the manual says it may require bifurcation whereas, again, the Sonnet Fusion explicitly does not.
There are off-brand cards as well. And 10Gtek sells NVMe carrier cards as well that do or do not need bifurcation. Most of what you’ll find is x8, though. 10Gtek has a x16 card, but I can’t find it for sale anywhere. And I may opt for a x8 card over the Sonnet Fusion since overall performance is unlikely to completely saturate the x8 interface under typical use cases. And PCI-E 3.0×8 is far, far more bandwidth than can be saturated with even 10GbE.
So stay tuned for updates.
Pool corruption!
So in the course of this upgrade, I suffered pool corruption. Talk about bad timing on it as well since it happened pretty much as I was trying to get the new mainboard online with my ZFS pool attached to it. So was it the non-ECC RAM? Have I been wrong this entire time and will now repent to the overlords who proclaim that one must never use non-ECC RAM with ZFS?
Yeah, no.
Initially I thought it was a drive going bad. TrueNAS reported one of the Seagate 10TB drives experienced a hardware malfunction – not just an “unrecoverable read error” or something like that. A lot of read errors and a lot more write errors being reported in the TrueNAS UI. And various error messages were showing on the console screen as well with the drive marked as “FAULTED”.
Thankfully Micro Center had a couple 10TB drives on hand, so I was able to pick up a replacement. Only to find out the drive wasn’t the issue as the new drive showed the exact same errors. The problem? The drive cable harness. If only I’d thought to try that first.
Something about how I was pulling things apart and putting them back together damaged the cable. And that it affected only one of the drives on the harness was the confusing bit. I’m sure most seeing what I observed would’ve thought the same, that the drive was going instead of the cable harness.
Unfortunately the back and forth of trying to figure that out resulted in data corruption errors on the pool, but thankfully to files that I could rebuild or re-download from external sources or restore from a backup. An automatic second resilver on the drive, which started immediately after the first finished, saved me from needing to do that and corrected the data corruption issue. At the cost of another 16 hour wait to copy about 8TB of data, about the typical 2 hours per TB I’ve seen from 7200RPM drives. (5400RPM drives tend to go at 2.5 hours per TB.)
So lesson learned: if TrueNAS starts reporting all kinds of weird drive errors out of the blue, replace the drive cable harness first and see if that solves the problem.
On the plus side, I have a spare 10TB drive that I thought was dead. But it came at a cost I wouldn’t have had to spend if I was a bit more diligent in my troubleshooting. Again, lesson learned.
Since the resilver finished, the pool has been working just fine. Better, actually, than when it was attached to the AMD FX, though the cooling fan on the SAS card is probably helping there, too.
You must be logged in to post a comment.